This topic has been well covered by StarkWare and recently Vitalik has a detailed post about layer 3s. So, do I have anything to add? I always thought I did not, which is why I never wrote on the topic - and it’s been a good ~10 months since I first discussed this topic with the StarkWare folks. But today, I think I might be able ramble about it from a different perspective.
The first thing to understand is “web2” runs on 100,000,000 servers around the world. “Web3” is a rather silly meme, given it is explicitly a niche subset of “web2”. But let’s assume this blockchain stuff can create its small and sustainable - but lucrative - niche, appealing to scenarios which strictly require distributed trust models and relatively minimal compute (i.e. nothing like supercomputers with custom hardware encoding millions of videos in real time). Let’s say we’ll need only 0.1% of the compute capabilities of “web2”. That’s 100,000 servers to establish a small niche.
Now, let’s consider a high-TPS monolithic chain like BNB Chain or Solana. Though it may seem impressive by a security & decentralization priority chain like Bitcoin, it’s necessarily a mid-range server because you must get hundreds or thousands of entities to be in sync. Today, a higher end server will be 128 cores, not 12; with 1 TB RAM, not 128 GB, etc. Immediately, it seems absurd that 1 mediocre server will be able to meet the demand. Indeed, a single actually on-chain game will probably need multiple high-end servers with 10x Solana’s compute capability were it to be successful.
The next step is rollups. While the design space for a specialized execution layer is wide and evolving, I’m talking about rollups with 1-of-N trust assumptions. Because of the 1-of-N assumption (as opposed to 51%-of-a large M), there’s no longer a need to run thousands of nodes. So, ceteris paribus, a rollup can upgrade to a more performant server. ZK rollups have a particular advantage because many of the nodes can simply verify validity proofs - so you can only need a handful of full nodes with high-performance servers. Yes, you need provers, but these proofs only need to be generated once, and proving times continue to decrease with advancements in both software and hardware.
At some point, though, the rollup node becomes a bottleneck. Currently, the strongest bottleneck is state growth. Let’s assume state growth is solved, next up things get a little hazy, with some combination of bandwidth/latency or compute, depending on the scenario. As per Dragonfly’s benchmarks, even for a very mildly compute intensive usecase like AMM swaps, this limit is hit at 195 TPS for BNB Chain and 273 TPS for Solana. As mentioned earlier, rollups can push this farther alleviating the bandwidth bottleneck due to much fewer nodes to sync, but quickly you head up against the compute bottleneck. This is actually demonstrated by Solana’s devnet, which runs in a configuration more akin to a rollup, and does 425 TPS instead of 273 TPS.
Then comes parallelization. Rollups like StarkNet and Fuel V2 are focused on parallel execution; while it’s on the roadmap for other teams like Optimism. Theoretically, you can run multiple different dapps with different users on separate fee markets on multiple cores, but in practice, the gains achieved here are expected to quite limited. MEV bots are going to access all state at all times, and the fees will be set depending on the financial activity of the chain. So, in reality, you’d have one core bottlenecked. This is a fundamental limitation of smart contract chains. Which is not to say that the parallelism won’t help - it will. StarkNet’s approach with optimistic parallelism, for example, is a net positive for sure - as if the transaction can’t be parallelized it’ll just fall back to the primary core.
The idea that 64 core CPUs → 64x potential throughput is very false. Firstly, as mentioned above, parallel execution only helps in certain scenarios. The bigger issue, though, 64 core CPUs run with significantly lower single-threaded performance. For example, a 64-core EPYC runs at a core clock of 2.20 GHz, or 3.35 GHz boost; while a 16-core Ryzen 9 based on the same architecture clocks at 3.4 GHz, boosting to 4.9 GHz. So, the 64-core CPUs will actually be significantly slower for many transactions. As a side note, the latest 7th gen Ryzen 9 releasing in a couple of weeks boosts to 5.7 GHz on top of each core being 15% faster - so yes, with time compute capabilities do improve over time for everyone. But nowhere near as fast as many believe - a doubling nowadays takes a good 4-5 years.
So, because of the importance of the fast primary core, the maximum you can scale up to is 16 cores, as demonstrated above. (Incidentally, this is also why your cheap Ryzen 5 delivers 2x FPS as the 64-core EPYC at gaming.) But it’s unlikely those will be utilized, so we’re looking at a 2-5x uplift at best. For anything compute intensive, we’re looking at a few hundred TPS at best, for the fastest possible execution layer.
One tantalizing solution can be ASIC VMs - so basically you have a gargantuan single core that’s 100x faster than a regular CPU core. A hardware engineer tells me it’s trivial to turn the EVM into a lightning fast ASIC, but will cost hundreds of millions of dollars. Perhaps that’s well worth it for something settling as much financial activity as the EVM? The downside is we need to get to an ossified spec with state management and validity proofs (i.e. zkEVM) solved first - but something to look at for the 2030s perhaps.
Back to the here and now - what if we take the concept of parallelism to the next level? Instead of trying to cram everything into one server, why not expand things out on to multiple servers? That’s where we get layer 3s. For any compute intensive application, application-specific rollups are pretty much necessary. There are several advantages to this:
-
Fine-tuned for one application with zero VM overhead
-
No MEV, or limited MEV with easy solutions to mitigate harmful MEV
-
Dedicated fee market, also 2) helps a great deal. Additionally, you can have novel fee models for the best UX.
-
Fine-tuned hardware selected to a specific purpose (whereas a smart contract chain will always have some bottleneck unsuited for your application)
-
Solution to the transaction quality trilemma - you can have no/negligible fees but still evade spam through targeted DDoS mitigation. This works because the user can always exit to the settlement layer (2 or 1), retaining censorship resistance.
So, why not application-specific L1s, like Cosmos zones, Avalanche subnets, or Polygon supernets? The answer is simple: socioeconomic and security fragmentation. Let’s revisit the problem statement: if we have 100,000 servers and each has its own validator set - that’s obviously never going to work. If you have overlapping validators, each will need to run multiple supercomputers; or if each has its own validator set there’ll be very little security. Fraud proofs or validity proofs are the only way, for now. Why not Polkadot-like or NEAR-like sharding? There are strict limits - e.g. each Polkadot shard can only do a few dozen TPS, and there’ll only be 100 of them. Of course, they are well placed to pivot to the fractal scaling approach, and I expect them to - Tezos is leading the charge, of alt-L1s.
It’s important to note that the design scope for fraud and validity proven execution layers are very wide - so not everything needs to be a rollup. A validium is an excellent solution for most usecases settling lower value transactions or commercial transactions run by one application or company. It’s only the high-value decentralized financial stuff that require full Ethereum security needs to be a rollup, really. As honest-minority data layer ideas like adamantium and eigenDA mature, they can be nearly as secure as rollups in the long run.
I’ll skip the bits about how it works and such as Gidi from StarkWare and Vitalik have covered it better than I ever could. But the gist is: you can have 1,000 layer 3s, layer 4s or whatever on a layer 2 and all of it is settled with a single succinct recursive validity proof; only this needs to be settled on layer 1. So, you can do a gazillion TPS (with varying properties as mentioned above) verified by a single succinct validity proof. As such, the whole “layer” terminology is quite limiting, there’ll be all sorts of wild constructs if we ever get up to the 100,000 servers goal. Let’s just consider them rollups, validiums, volitions, or whatever, and discuss the security properties of each.
Now comes the elephant in the room: composability. Interestingly, validity proven execution layers can be atomically composable with its settlement layer, unidirectionally. The requirement is a proof is generated every block - we’re obviously not there yet, but it’s possible - proof generation is trivially parallelizable. So, you can have a layer 3 compose atomically with its layer 2. The issue is, you need to wait for the next block to compose back. For many applications, this is no issue at all, and these can happily remain on a smart contract chain. This can also potentially be solved if the layer 2 offers some form of pre-confirmations, so the transaction between L3 and L2 can actually be atomically composable.
The holy grail enters the fray when you can have multiple sequencers/nodes composing to a single unified state. I know teams from at least StarkWare, Optimism and Polygon Zero are working on related solutions. While I have zero understanding about the technical engineering required to make this happen, it does seem like something that’s well within the realms of possibility. Indeed, Geometry is already making in-roads into this with Slush!
This is what true parallelism looks like. Once this is figured out - you can actually have massive fractal scaling with minimal compromises to both security and composability. Let’s recap, then: you have 1,000 sequencers composing to a unified state, a single succinct validity proof, which is all you need to verify all of those 1,000 sequencers. So, you inherit root of trust from Ethereum, you retain full composability, some inherit full security, some partial, but in each case is an absolutely massive net benefit over running 1,000 heavily fragmented monolithic L1s in terms of scalability, security, composability and decentralization.
I expect the first application-specific L3s to go live over L2 StarkNet later this year. Of course, we’ll first see existing L2s make a move. But the true potential will be unleashed with novel applications we haven’t seen before, which are only really possible at scale with fractal scaling. On-chain games or similar projects like Topology’s Isaac or Briq will likely be the first ones to deploy their own L3s.
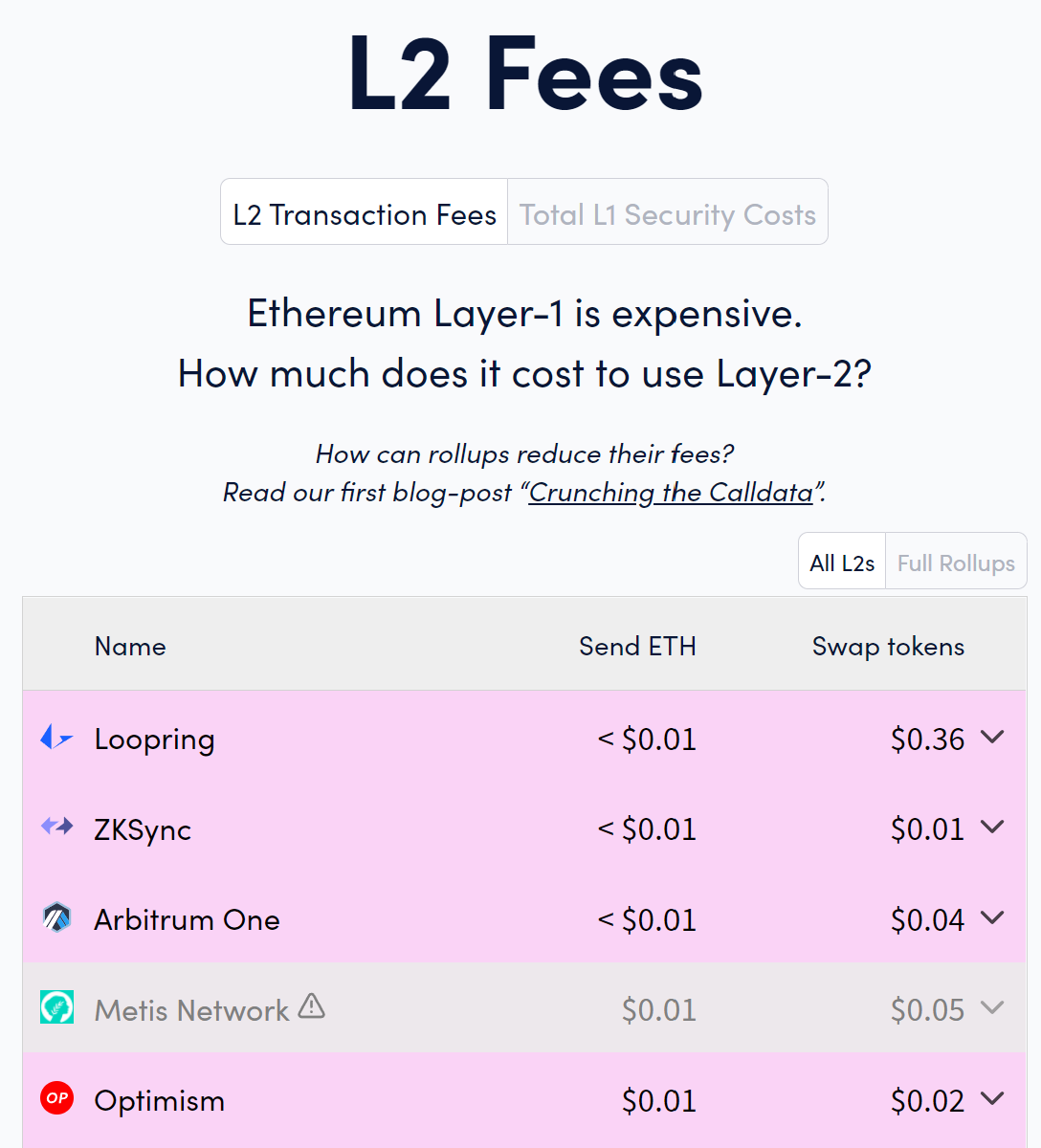
It’s pretty rich we’re talking about fractal scaling here where currently rollup fees are sub-cent (and indeed, $0.00 for Immutable X, Sorare etc.), and yet they are barely utilized at all. Which brings me back to the true bottleneck in the blockchain space - novel applications. It’s not a chicken and egg scenario anymore - we have plenty of empty blockspace yesterday and today with no demand. It’s about time we focused on building novel applications that uniquely leverage blockchain’s strengths, and build some real consumer and enterprise demand. I’m yet to see enough commitment from the industry or investors - app-layer innovation has been pretty much non-existent since 2020. (And no, kwonzifying existing “web2” concepts don’t count) Needless to say, without these applications, any type of scaling - fractal or otherwise - is a complete waste.